Building a metadata database with AI agents
TL;DR: I revisited a 20 year old side project to build a database of metadata about opera recordings and restructured it to optimize for AI agents doing the heavy lifting of domain-aware data entry. In the process I learned a lot about building applications where agents make up a class of users.
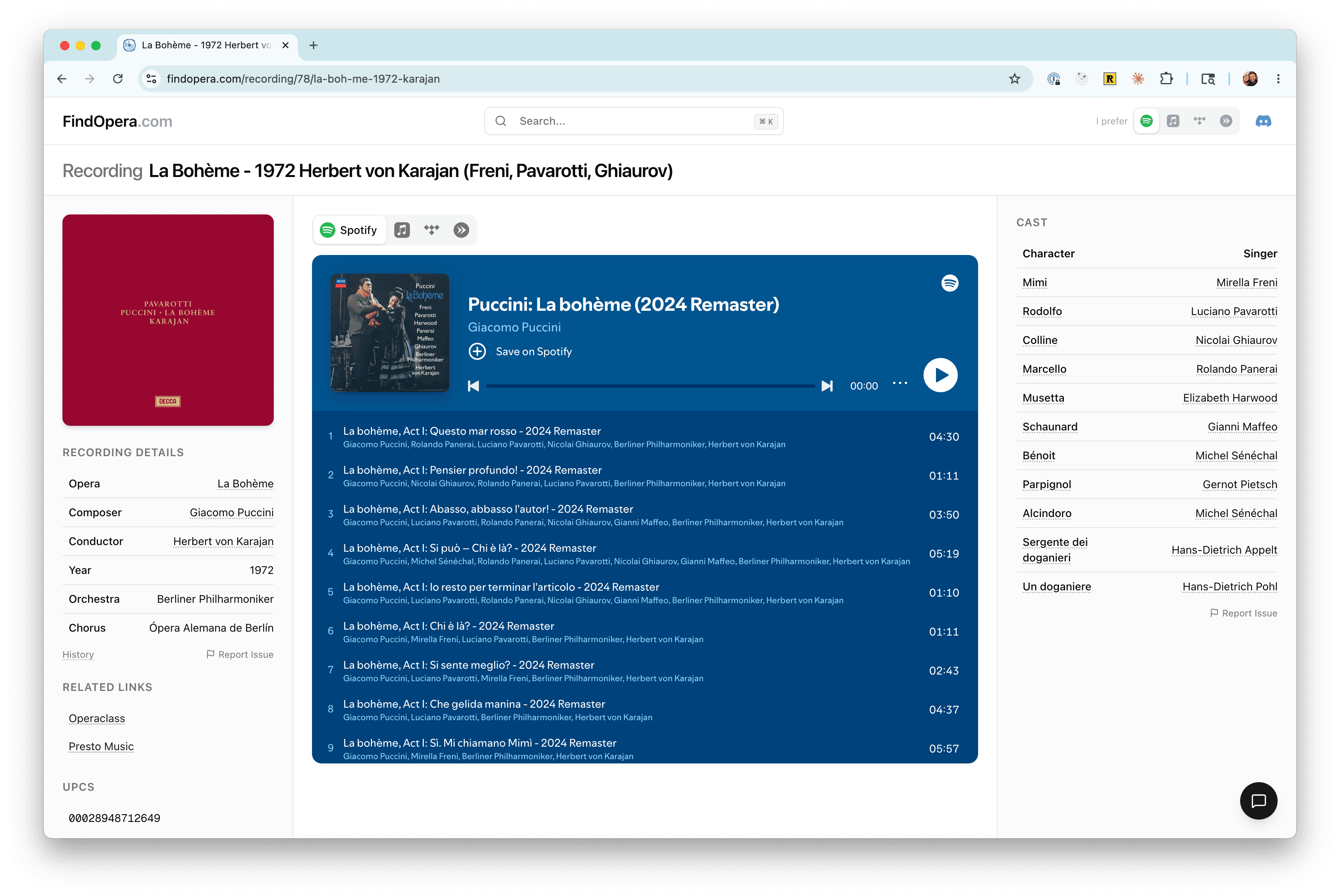
I am a self-taught software engineer and the first significant project I undertook, back in high school, was a web-based database to organize metadata about opera recordings. It was an excellent learning experience and every few years I’ve rebuild it using whatever modern stack I'm interested in learning. I can count at lest four major iterations since the early 2000s.
Despite all these rewrites I never really “finished” the project. That’s because the main bottleneck for this project was never actually software. It was data entry. I spent an uncountable number of late nights as a teenager painstakingly transcribing cast lists from various online sources and matching singer/character/composer/operas names with their canonical record in my database. Even with this effort my throughput was quite limited and, if I'm perfectly honest, error-prone. Here’s what the task of data entry actually looks like:
Trawling the unstructured web for pages with casts lists or liner notes describing the details of a recording
Parsing this information, which requires some domain knowledge such as an understanding that the largest name on an album cover is generally the composer and the second largest is the conductor, and cast lists are usually given in character name/singer name pairs.
Linking names to records. This involves some language skills and domain knowledge in order to correctly navigate things like differing transliterations of Russian names, and characters having nick names or being given in different languages depending on the country in which the recording was produced or the language in which it was recorded.
These are all tasks that LLMs are quite good at! So I decided it was time for yet another iteration of this project with today’s modern stack, which included a suite of AI agents (Claude Skills) to contribute metadata.
I then wrote a suite of agents to automate populating structured metadata. For example:
Find all the opera recordings on Spotify, find or create each recording in the database, and link the Spotify ID to that recording. Note that creating a recording requires searching the web for authoritative cast details.
The playbook looked something like this:
Make it work
Point an agent at a data source and ask it to manually scrape some number of items from the source and contribute the information it finds as structured data to FindOpera.
Ask the agent to reflect on how its doing the work and formalize its process as a skill file.
Make it right
Have it run the process some more times and then reflect on how it can improve its own process (skill file) to improve accuracy.
Repeat until accuracy is acceptable
Make it fast
Ask the agent to reflect on what’s slowing it down and causing it to consume tokens. Have it write scripts for itself to automate deterministic parts of the process.
Repeat until efficiency hits a ceiling
Make it scale
Have the agent scale up and spawn subagents to efficiently digest all records in the data source.
Trust but verify #
This process works well for inputing lots of data, but the quality of the data is hard to reason about. Here’s where the wiki-style database with required comments came in handy. As I built the agents I asked them to always include a comment which justified their contribution and which cited its source with a URL.
This meant that I was then able to build a verification agent which runs after the fact and re-verifies the edits made by other agents by confirming the cited source does indeed include the factual information that the agents added/edited. This agent would then either independently verify the fact (and provide a source) or revert the change.
What I learned #
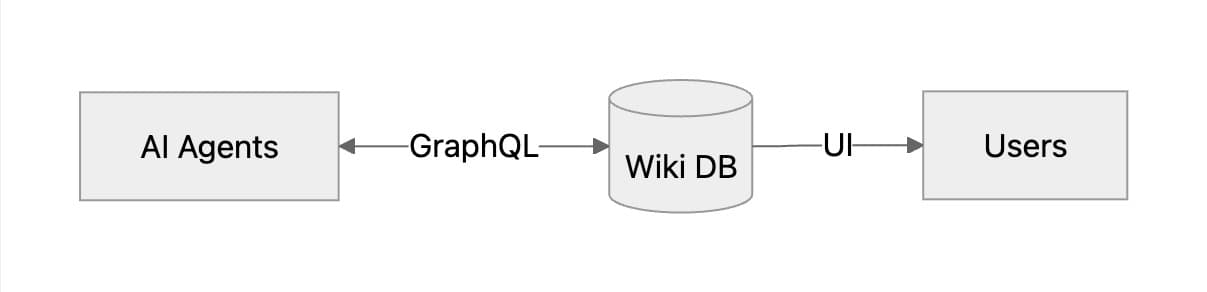
GraphQL is just “ok” as a generic interface for agents #
GraphQL is a reasonable API for agents, but not great. Providing a GraphQL API for agents to interact with worked much better than giving the agent direct database access since it allowed me to enforce some number of invariants which acted as guard rails for the agents.
Agents were good at writing syntactically valid GraphQL but were quite prone to making assumptions about the schema. Helpful error messages from the server like “Unknown field name, did you mean fullName?” helped it course correct and eventually find the correct query structure, making raw introspection queries and even reading the GraphQL schema directly were both relatively inefficient.
Additionally, the JSON response from the server, where each fields name in a list is restated was relatively bad for token usage. Almost every process ultimately ended up improved by either canonicalizing which queries to use in a skill, or wrapping the GraphQL call in a script which could reformat the returned data in a terser format.
Overall GraphQL is an effective API for agents to interact with a service like this, but relatively inefficient both in terms of the number of iterations it required but also the tokens required to parse the results.
Wiki-style databases with explicit sources are great for agents #
All users are error prone, and agents are no exception. In fact, the scale of agents means they can make mistakes much more prolifically than users. However, by forcing agents to cite their sources and making the history transparent, it allows higher-order “validating” agents to fact-check the work of the data collecting agents. This basically means the degree of accuracy in the database is more or less a function of how many tokens I want to spend. I’m especially optimistic about this architecture long term. As agents get smarter and more capable, I expect I’ll be able continue to refine the data such that the work of less capable agents will remain valuable even as future agents become more capable.
The economics of agents #
Historically side projects felt very empowering as a software engineer. With open source software I could build something, run it on a cheap VPS and build something that an arbitrary number of users could enjoy for ~zero cost. With AI agents this dynamic is different. Not only does it cost money/tokens to build a vibe coded app, but using agents for data entry/scraping means that my costs scale relative to the amount of data I want to collect. This means it’s not sustainable to build an app like this “just for fun” without some way to recoup the cost. The dynamic felt much more like hiring a data entry specialist and then building processes/tools to get the most value out of their time than building just for fun. At times I felt more like a manager than a software developer.
In my case I initially justified the cost (Claude Max) as a profession educations/self improvement expense. However, before after about a month I was admitted to Anthropic’s open source program which subsidized by expenses.
Luckily the total number of opera recordings is large bug bounded, which means I can reasonably expect to be able to index basically every commercially available recording with a single Max subscription.
The open web is closing #
Many websites which have data which would be useful to my agents have already started closing off their sites to bot users, and I can see why. My agents were prolific and could make many hundreds or thousands of requests to a site in an hour and, from the perspective of the site maintainers, are basically parasitic. They don’t look at ads, and are taking data to provide a service which may even compete with these sites by making the same data avaiable elsewhere.
I expect this trend will continue to accelerate and that the window where a project like this is viable is closing.